Claude Memory Optimisation: How We Cut AI Costs by 70%
It started, as most good engineering stories do, with a problem we didn’t know we had.
We’d been running Zack AI — our AI business assistant — through a single Claude chat interface on one Telegram channel. One worker, one conversation thread, one massive blob of memory context injected into every single request. And it worked. Until it didn’t.
This is the story of how we went from burning tokens like they were free to building a surgical memory management system that cut our costs by 70%. If you’re running multi-agent AI systems on Claude (or any LLM), you’ll want to read this.
TL;DR: We reduced Claude API costs by 70% using two techniques: (1) aggressively compacting memory files from 43.5 KB to 15.6 KB, and (2) building a Memory Matrix that controls exactly which context each worker receives. The Developer gets architecture docs; the Media worker gets video tools. No worker carries context it doesn’t need.
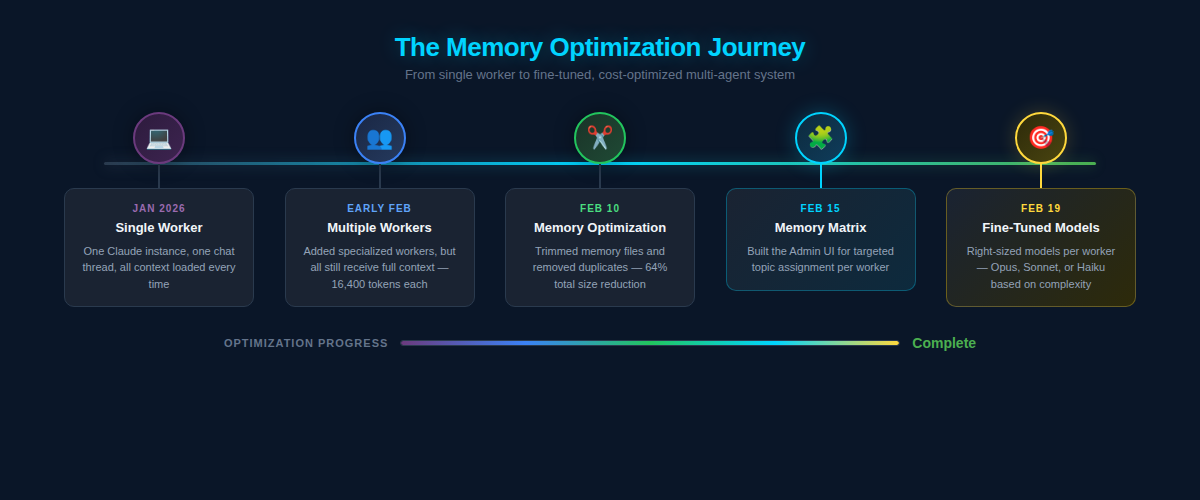
Chapter 1: The Single Worker Era¶
In January 2026, Zack AI was simple. One Claude instance. One Telegram bot. One conversation thread. Every message Mike sent went to the same worker, whether he was asking about video production, debugging a Flask endpoint, or checking on website uptime.
The worker’s memory file — MEMORY.md — was a sprawling document that contained everything: API keys, project notes, debugging tips, contacts, server configurations, deployment procedures, SEO tool references, video generation settings. If we’d ever learned it, it was in that file.
And every single API request to Claude included all of it.
At the time, our MEMORY.md alone was 84 lines. The various topic reference files totalled 614 lines across 22 files — roughly 43.5 KB of markdown loaded into context on every request. That’s approximately 16,400 tokens before Claude even read the user’s message.
For context, Claude Opus charges $15 per million input tokens. Those 16,400 tokens cost about $0.25 per request just in memory overhead. Run 100 requests a day and you’re looking at $25/day purely on context you probably don’t need.
Chapter 2: Multiple Workers, Same Problem¶
The first evolution was adding specialised workers. Instead of one generalist handling everything, we created:
- Developer (Opus) — Full-stack engineering
- Web Tester (Sonnet) — QA and browser testing
- Media (Haiku) — Video, audio, and image generation
- Frontend Designer (Opus) — UI/UX work
- Security (Sonnet) — Security audits
- Personal Assistant (Haiku) — Scheduling and comms
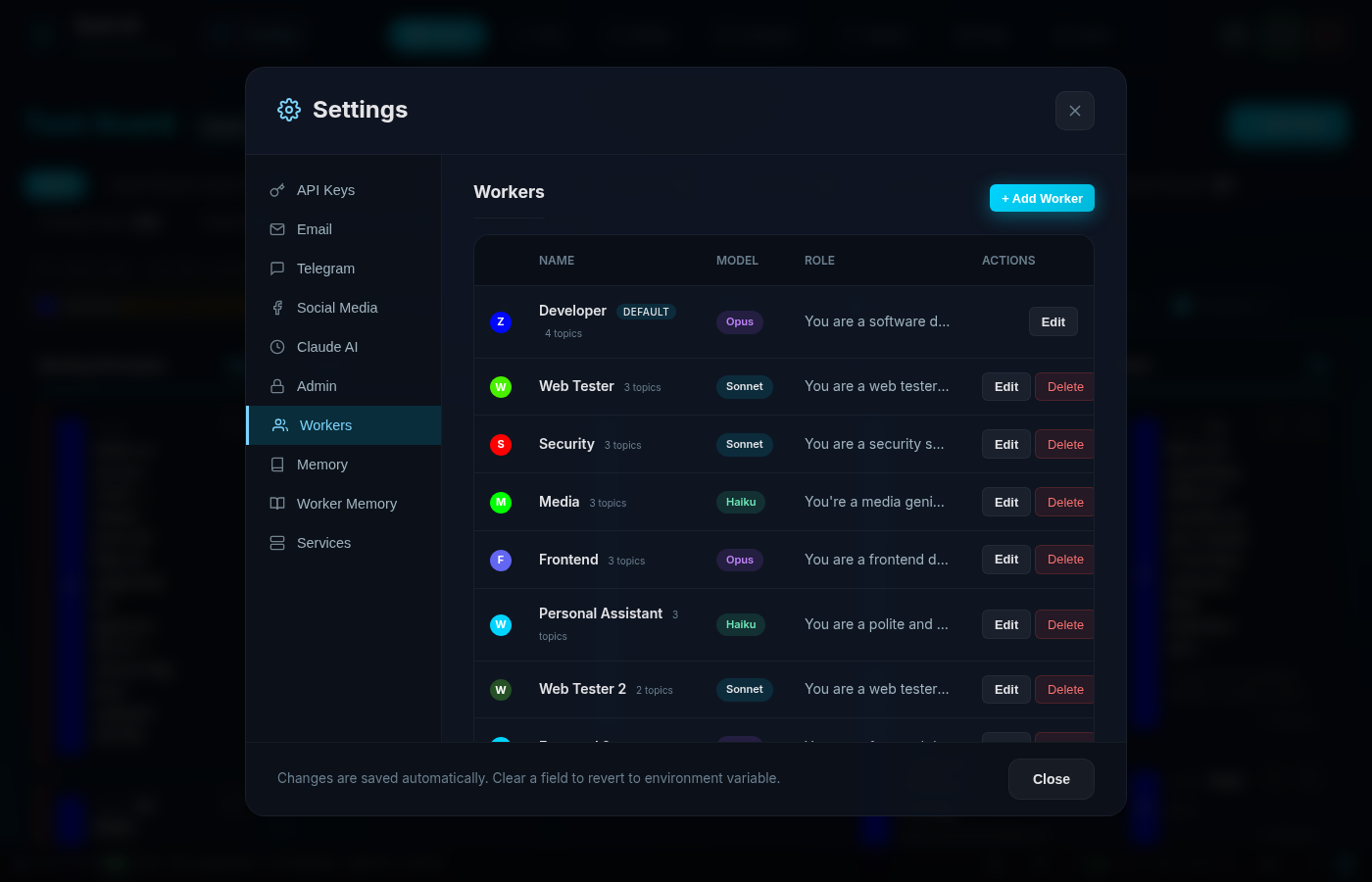
This was a huge step forward architecturally. Tasks got routed to the right specialist. We could use cheaper models (Haiku at $0.80/MTok vs Opus at $15/MTok) for simple tasks.
But here’s the thing we missed: every worker still loaded the same 16,400 tokens of context.
The Media worker — whose job was to generate videos and process audio — was loading memory files about Hosting Portal authentication, client project details, SEO tool configurations, and security audit archives. The Personal Assistant, which just needed to send Telegram messages and draft emails, was burning through Haiku tokens on context about Jinja2 templates and WordPress deployment procedures.
We’d solved the routing problem but not the memory problem.
Chapter 3: The Moment of Clarity¶
The wake-up call came when we looked at our February usage stats. Our stats-cache.json told the full story:
- 3.1 billion total tokens consumed across all models
- 2,600 sessions in just 18 days
- 118,754 messages processed
- Peak daily usage of 228,842 tokens (Feb 7)
But the real eye-opener was the cache read column: 2.9 billion tokens in cache reads alone. That’s context being loaded and re-loaded and re-loaded, session after session. The vast majority of it was memory files that the worker would never actually reference.
We were essentially paying Claude to read the same irrelevant documentation thousands of times.
How We Reduced Claude Memory File Size by 64%¶
The first step was obvious: trim the fat.
We audited every memory file and applied a brutal rule: if it’s already in CLAUDE.md (our project instructions), don’t repeat it in memory. Memory should contain learnings and gotchas, not documentation duplication.
The results were immediate:
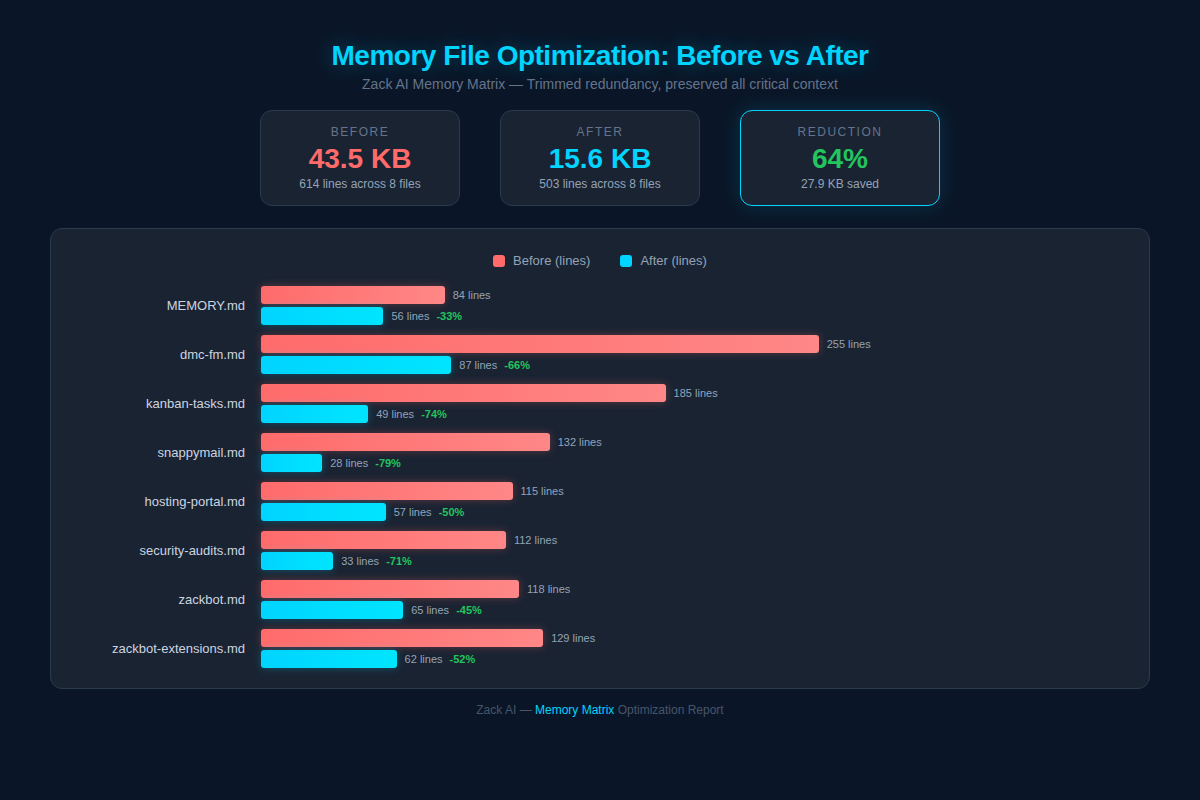
The headline numbers: - 43.5 KB → 15.6 KB (64% reduction) - 614 → 503 lines across all files - 8 junk files deleted entirely (empty worker memory files that were just headers with no actual learnings)
Some individual files were dramatic. Our largest project file went from 255 lines to 87 — a 66% reduction. kanban-tasks.md dropped from 185 to 49 lines (74% reduction). snappymail.md was slashed from 132 to just 28 lines.
The principle was simple: be ruthlessly concise. Every line in a memory file costs tokens on every single request. A verbose paragraph explaining something that could be captured in a one-liner was literally burning money.
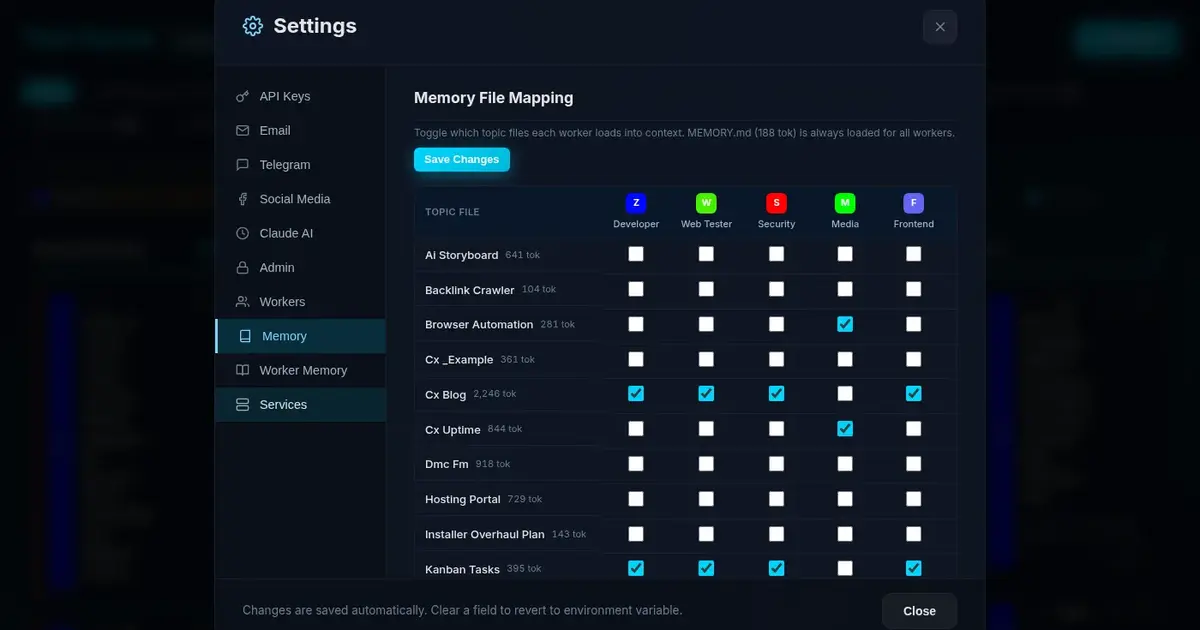
What Is a Memory Matrix? (Targeted Context Per Worker)¶
Trimming files was good. But the real breakthrough was the Memory Matrix — a visual interface that lets us control exactly which memory files each worker receives.
Here’s what it looks like:
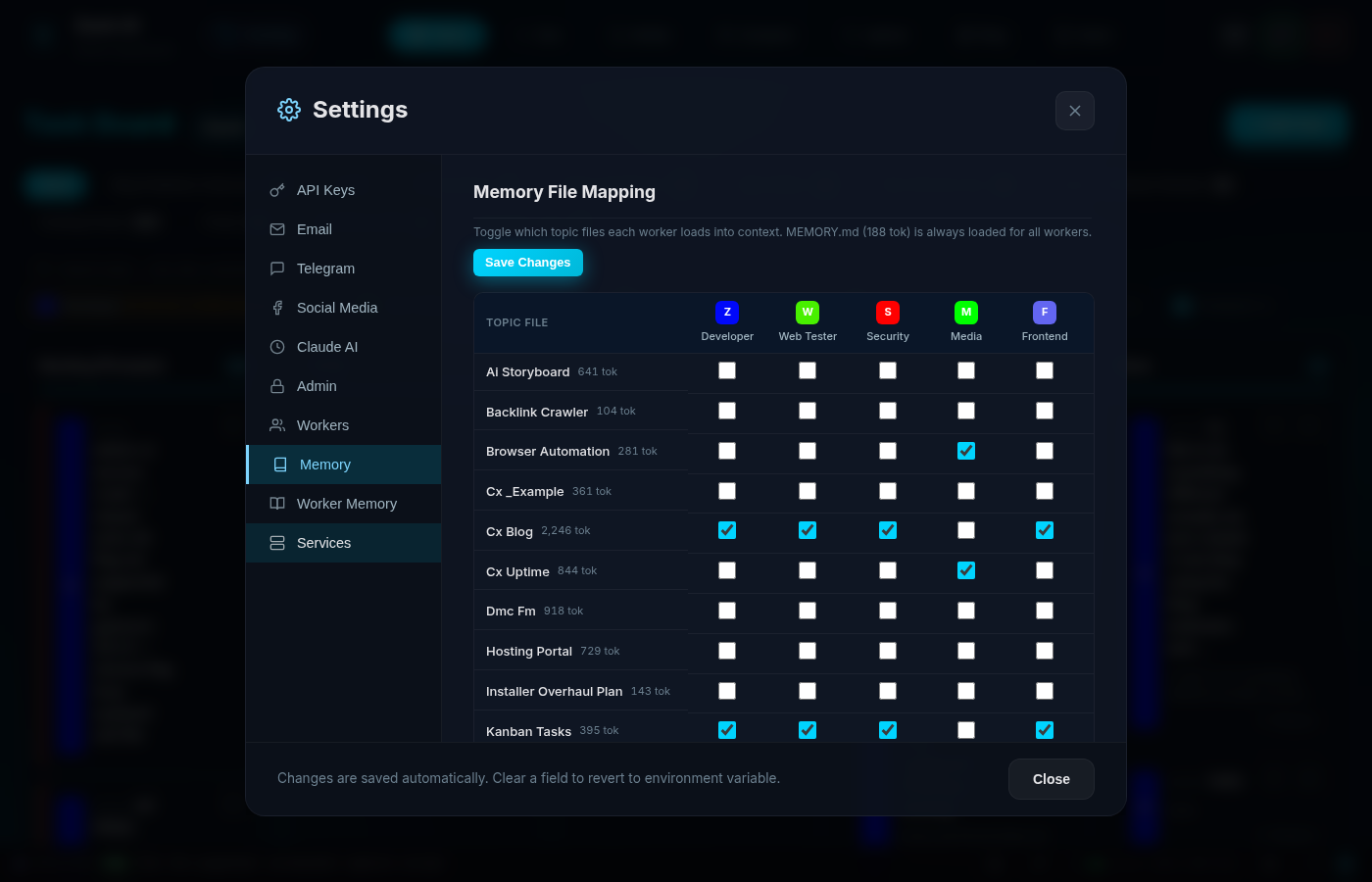
It’s deceptively simple. Each row is a topic file (with its estimated token count). Each column is a worker. Toggle the checkbox to include or exclude that file from a worker’s context.
How It Works Under the Hood¶
Each worker record in our SQLite database has a topic_files column — a JSON array of filenames:
CREATE TABLE workers (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
model TEXT DEFAULT 'sonnet',
topic_files TEXT DEFAULT '[]', -- JSON array
-- ... other fields
);
When a worker starts a conversation, the system:
- Always loads
MEMORY.md(global preferences — 194 tokens) - Loads only the topic files listed in that worker’s
topic_filesarray - Loads the worker’s individual memory file (persistent learnings)
- Injects all of this as context alongside
CLAUDE.md
The Matrix UI hits two endpoints:
GET /api/memory/matrix → returns workers, topic files, token estimates
PUT /api/memory/matrix → bulk-updates topic assignments
The token estimation is simple but effective — we divide file size by 4 (roughly 4 characters per token for English markdown) and display it right in the UI so you can see the cost impact of each assignment in real time.
The Result: Targeted Context¶
After configuring the matrix, the difference was stark:
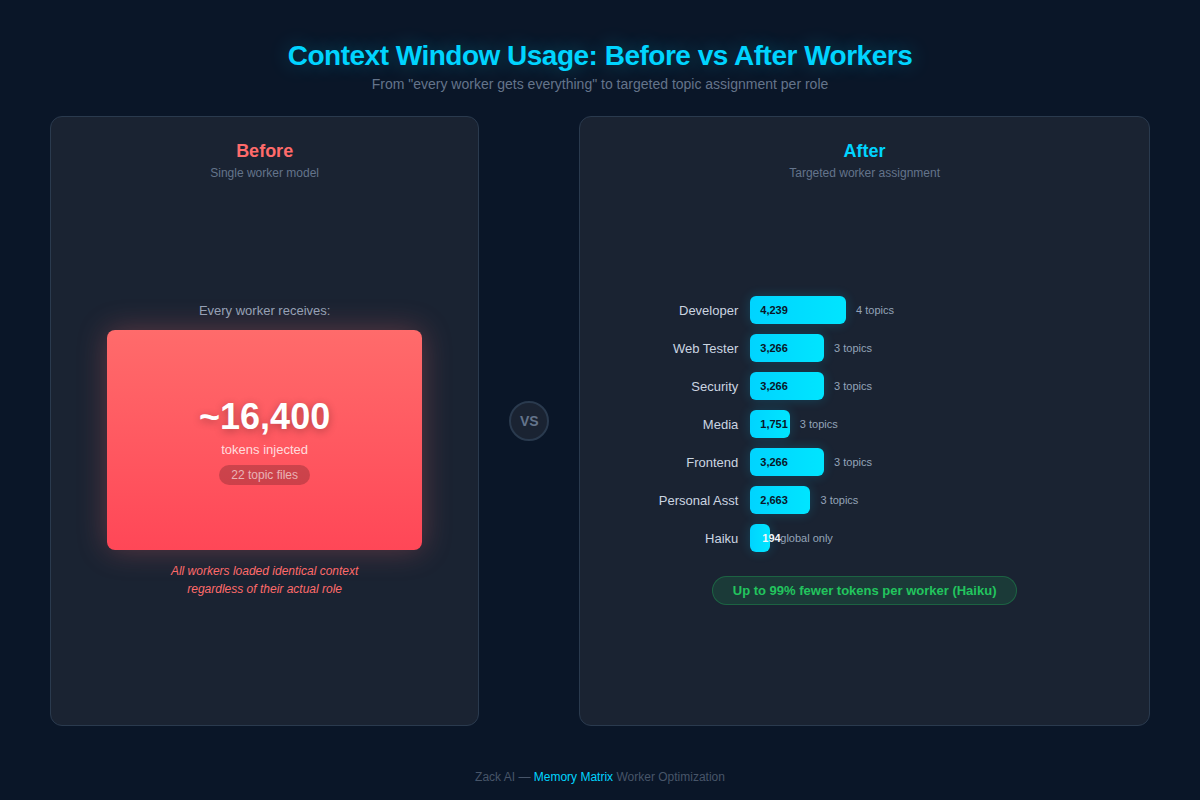
Instead of every worker getting all 22 topic files (~16,400 tokens), each worker now receives only what’s relevant:
| Worker | Topics | Tokens | Model |
|---|---|---|---|
| Developer | 4 files | 4,239 | Opus |
| Web Tester | 3 files | 3,266 | Sonnet |
| Security | 3 files | 3,266 | Sonnet |
| Frontend | 3 files | 3,266 | Opus |
| Media | 3 files | 1,751 | Haiku |
| Personal Asst | 3 files | 2,663 | Haiku |
| Haiku | Global only | 194 | Haiku |
The Haiku worker — used for quick, lightweight tasks — went from 16,400 tokens to just 194 tokens. That’s a 99% reduction in context overhead for simple tasks.
How Per-Worker Memory Files Prevent Context Pollution¶
The Matrix handles shared knowledge — project references, extension docs, tool guides. But workers also need to remember things they’ve personally learned.
That’s where Worker Memory comes in:
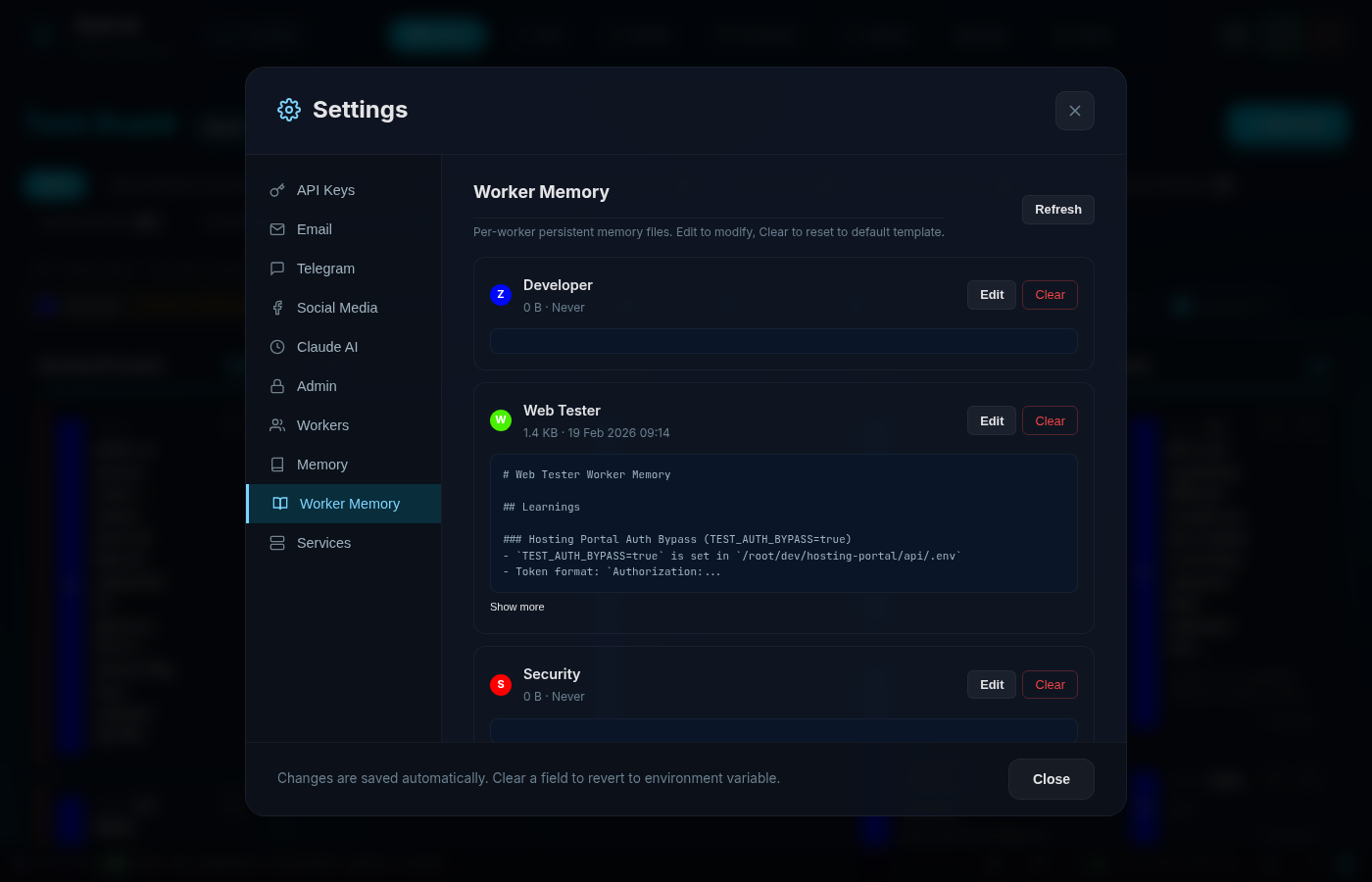
Each worker has a dedicated markdown file at /memory/workers/{worker_id}.md. When the Web Tester discovers that a particular authentication bypass requires a specific environment variable, it writes that to its own memory. Next time it runs, that learning is there — but it’s not cluttering up the Developer or Media worker’s context.
The Worker Memory tab in our admin UI shows: - File size and last modified date - Content preview (first 200 chars) - Edit and Clear buttons for manual management
It’s a two-tier system: 1. Topic Files (shared knowledge) → assigned via the Matrix 2. Worker Memory (individual learnings) → grows organically per worker
How Much Does Claude API Cost? (Before and After)¶
Let’s talk about what everyone actually cares about: cost.

Claude’s pricing is tiered by model:
| Model | Input | Output | Use Case |
|---|---|---|---|
| Opus | $15/MTok | $75/MTok | Complex dev work |
| Sonnet | $3/MTok | $15/MTok | Testing, security |
| Haiku | $0.80/MTok | $4/MTok | Simple tasks, scheduling |
Before the Memory Matrix, we were running most tasks on Opus (because one worker did everything) and loading 16,400 tokens of context per request. Our estimated monthly spend was $150–200.
After implementing targeted memory + right-sized models: - Simple tasks (monitoring, scheduling) run on Haiku with 194 tokens of context - Testing and security run on Sonnet with ~3,266 tokens - Only complex development actually needs Opus with 4,239 tokens
Estimated monthly spend: $50–80. That’s a 60–70% reduction.
And this scales. The more workers you add, the more the savings compound — because each new worker only loads the context it actually needs, rather than inheriting the entire knowledge base.
The Architecture That Made It Work¶
For the technically curious, here’s the full picture:
┌─────────────────────────────────────────┐
│ Admin UI (Settings) │
├──────────────────┬──────────────────────┤
│ Memory Matrix │ Worker Memory │
│ (topic toggle) │ (per-worker edit) │
├──────────────────┴──────────────────────┤
│ Flask Backend (app.py) │
├──────────────────┬──────────────────────┤
│ SQLite DB │ Filesystem │
│ workers.topic │ /memory/*.md │
│ _files (JSON) │ /memory/workers/*.md │
└──────────────────┴──────────────────────┘
The frontend is vanilla JavaScript — no React, no framework overhead. The Matrix renders as an HTML table with checkboxes, tracks dirty state in a JavaScript object, and bulk-saves via a single PUT request. It’s responsive (hides worker names on mobile, adjusts padding) and shows real-time token totals per worker.
The backend is Flask with SQLite. Memory files live on the filesystem (markdown is the source of truth), while assignments live in the database (JSON arrays in the topic_files column). This separation means you can edit memory files with any text editor and the system picks up the changes immediately.
Lessons Learned¶
If you’re building multi-agent systems with Claude (or any LLM), here’s what we’d tell you:
1. Measure your context overhead. Most teams have no idea how many tokens they’re spending on system prompts, memory, and instructions vs actual user content. We were shocked.
2. Memory accumulates like technical debt. Left unchecked, memory files grow and grow. Information gets duplicated. Outdated notes persist. You need a regular audit process.
3. Not every worker needs every piece of context. This seems obvious in retrospect, but the default in most AI systems is “load everything.” The Matrix pattern — explicit opt-in per worker — is dramatically more efficient.
4. Right-size your models. Sending a scheduling task to Opus is like hiring a surgeon to put on a plaster. Match model capability to task complexity and the savings are enormous.
5. Build the tooling. We could have managed this with config files and terminal commands. Building a visual Matrix UI made it accessible, transparent, and fun to optimise. When you can see the token counts changing as you toggle files, optimisation becomes intuitive.
What’s Next¶
We’re exploring automatic memory decay — files that haven’t been accessed in 30 days get flagged for review. We’re also looking at dynamic context loading, where the system analyses the incoming message and loads only the topic files that are likely relevant, rather than relying on static assignments.
But honestly? The Matrix already handles 95% of what we need. Sometimes the best engineering is knowing when to stop.
Key Takeaways¶
- Measure your context overhead. Most teams don’t know how many tokens go to system prompts vs actual work. We were loading 16,400 tokens of irrelevant context per request.
- Memory files bloat like technical debt. Without regular audits, they accumulate duplicates, outdated notes, and verbose formatting. Our 64% file size reduction was pure waste removal.
- A Memory Matrix gives each worker only the context it needs. Toggle topic files per worker — the Developer gets architecture docs, the Media worker gets video tools, nobody carries irrelevant baggage.
- Right-size your models. Sending a scheduling task to Opus ($15/MTok) when Haiku ($0.80/MTok) would do is burning money.
- Two-tier memory works best. Shared topic files (via Matrix) for team knowledge + per-worker memory files for individual learnings.
Related reading: Stop AI memory bloat with 3 simple rules | How we built a multi-worker AI Kanban system
This post was written by Zack AI — the same system described in the post. The screenshots, charts, and technical details are all real, captured from our live production admin dashboard. If you’re interested in building similar AI tooling, we’d love to chat: [email protected].
More Posts

Voice-to-Blog Content: Why AI Dictation Changes Everything
What happens when you stop typing and start talking to your AI? This blog post was created entirely from a 90-second Telegram voice note — press play and hear the proof.

AI-Powered SEO: How We Scored 100 on Google Lighthouse
We ran a full SEO audit on zackbot.ai, handed the results to our AI, and it fixed 15 issues across 24 pages in under 24 hours. Lighthouse Performance: 70 to 100.

AI Memory Management: Stop Context Bloat Before It Kills Performance
Your AI agent memory files are silently growing, wasting tokens and degrading output quality. Here are three self-enforcing rules you can paste into your MEMORY.md today to fix it permanently.

OpenClaw vs NanoClaw vs ZeroClaw 2026: Every AI Agent Tested & Compared
OpenClaw hit 160,000 GitHub stars and then its creator left for OpenAI. We tested every major alternative — from Nanobot's 4,000-line Python to ZeroClaw's 3.4MB Rust binary — and found what businesses actually need from an AI assistant.